웹 페이지 종류
- 정적 페이지 : 웹 브라우저에 화면이 한번 뜨면 이벤트에 의한 화면의 변경이 없는 페이지
- 동적 페이지 : 웹 브라우저에 화면이 뜨고 이벤트가 발생하면 서버에서 데이터를 가져와 화면을 변경하는 페이지
requests
- html 문자열로 파싱 : 주로 정적 페이지 크롤링
- json 문자열로 파싱 : 주로 동적 페이지 크롤링
selenium
- 브라우저를 직접 열어서 데이터 받음
크롤링 속도
- requests json > requests html > selenium
KOSPI 일별 시세 데이터 조회 - naver
코스피 - 네이버 증권
관심종목의 실시간 주가를 가장 빠르게 확인하는 곳
m.stock.naver.com

** 웹크롤링 기본 순서 **
- URL 파악(웹 페이지 분석*****)
- 서버에 데이터 요청 : request(url) → response(data) : json(str), html(str)
- 데이터 형태 변경 : json(str) → list, dict → DataFrame
< 웹페이지는 크롬브라우저에서 진행함 >
1. URL 파악 (웹 페이지가 복잡하여 mobile 웹페이지에서 수집)
1.1 URL 파악하기
1) [ 개발자 도구(F12) | 마우스 오른쪽-검사 ]로 들어감
2) 상단 : "네트워크" 클릭 - "Fetch/XHR" 클릭
3) "클리어" | "삭제" 클릭 : 기록된 로그 삭제
4) 일별시세에서 더보기 클릭

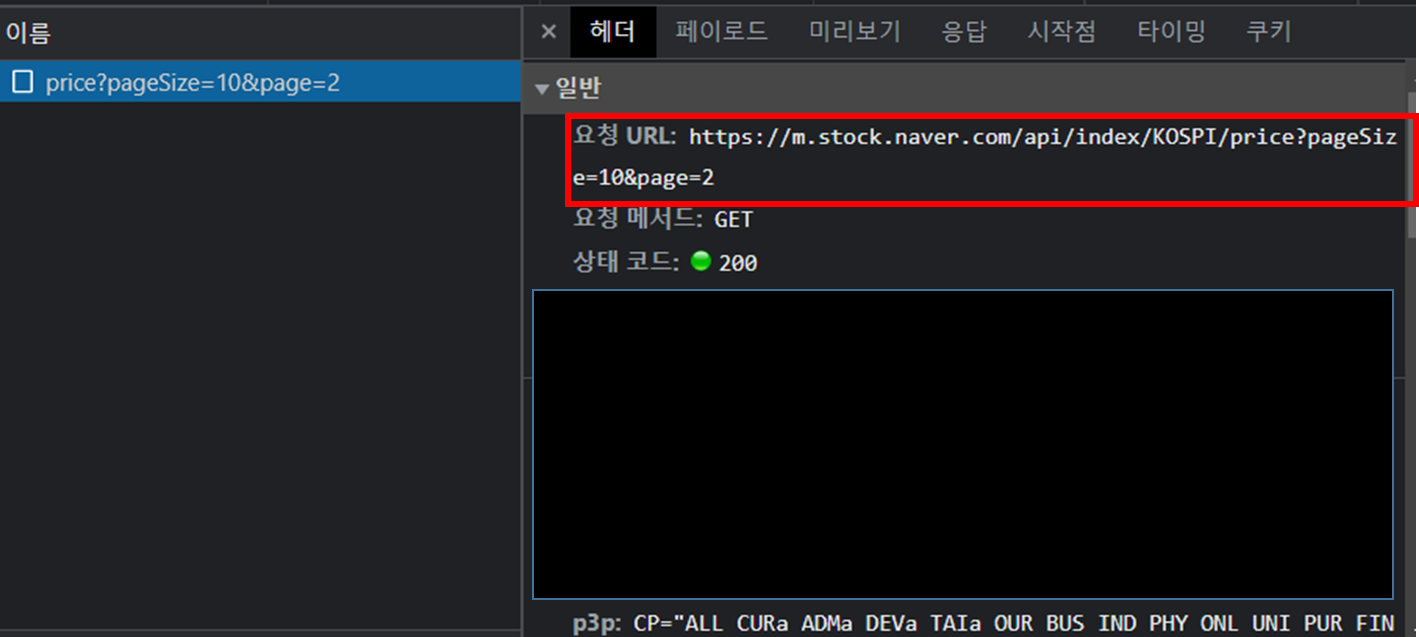
- 클리어 → 일별시세 더보기 클리시 밑에 사진과 같은 로그 나타남
- 로그 클릭시 헤더, 페이로드, 미리보기 확인할 수 있음
- 여기서 나타난 요청 URL이 크롤링에 필요한 URL임
1.2 코드
- 라이브러리
import warnings
import requests
import pandas as pd
warnings.filterwarnings('ignore')
- url 불러오기
# https://m.stock.naver.com/api/index/KOSPI/price?pageSize=10&page=2 : 복사 주소
pagesize, page = 10, 1
url = f'https://m.stock.naver.com/api/index/KOSPI/price?pageSize={pagesize}&page={page}'
print(url)https://m.stock.naver.com/api/index/KOSPI/price?pageSize=10&page=1
=> 1.1에서 찾은 URL을 값 복사를 이용해 불러옴
=> pagesize와 page는 값을 변경하여 불러올 수 있기 때문에 f-string을 사용하여 변수명으로 작성해 줌
=> page는 일별시세 더보기와 관련 있음. pagesize는 수와 관련 있음.
2. 데이터 요청 : request(url) → response : json(str)
- request(url)
# 200이면 정상적으로 요청 됨 // 403이나 500이면 url 잘못된 것
response = requests.get(url)
response<Response [200]>
- 서버에서 받은 문자열 확인
# 문자열 받은 것까지 확인(json 형태)
response.text[:100]'[{"localTradedAt":"2023-03-27","closePrice":"2,409.22","compareToPreviousClosePrice":"-5.74","compar'
=> json 형태로 문자열 받음
3. 데이터 형태 변경 (파싱) : json(str) → list, dict → DataFrame
- response 데이터 타입 확인
# response 데이터 타입 확인
type(response)requests.models.Response
=> Response 데이터 타입
- list로 변환
# json(str) > list
data = response.json()
type(data)
- DataFrame 변환
kospi = pd.DataFrame(data)
kospi.head()
=> 크롤링을 하여 데이터프레임 형태로 최종 생성함
환율 데이터 조회 - daum
환율 | 다음 금융
finance.daum.net
<위 링크로 페이지에 들어간 후, 개발자 도구 켜기>
<개발자 도구에서 네트워크 탭 클릭, Fetch/XHR 클릭 후 새로고침>
<가장 위에 summaries 클릭하여 헤더 확인>
1. url + 2. 데이터 요청
# 1. 웹서비스 분석 : URL
url = 'https://finance.daum.net/api/exchanges/summaries'
# 2. request(URL) > response(DATA) : DATA(json(str))
response = requests.get(url)
response<Response [403]>
=> 200이면 정상적으로 요청 됨 // 403이나 500이면 url 잘못된 것 : 해당 데이터 요청은 잘못됨
해결방법은 user-agent, referer 같은 header를 추가해야 된다는 것!
https://stackoverflow.com/questions/38489386/python-requests-403-forbidden
Python requests. 403 Forbidden
I needed to parse a site, but i got an error 403 Forbidden. Here is a code: url = 'http://worldagnetwork.com/' result = requests.get(url) print(result.content.decode()) Its output: <html> ...
stackoverflow.com
<여기서 참고함>
# URL 분석
url = 'https://finance.daum.net/api/exchanges/summaries'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.54',
'referer' : 'https://finance.daum.net/exchanges'
}
# request(URL) -> response(DATA) : DATA(json(str))
response = requests.get(url, headers=headers)
response<Response [200]>
=> "user-agent" 넣고 실행한 결과, 여전히 403 오류가 발생하여 referer로 추가했다.
=> headers 정보들은 요청헤더에서 확인할 수 있다.
# DATA(json(str)) -> list, dir -> DataFrame
data = response.json()
pd.DataFrame(data).head()
=> 크롤링을 하여 데이터프레임 형태로 최종 생성함
***
url을 확인하고, 서버에서 데이터 요청을 받기 위해 웹 페이지 분석하는 것이 가장 중요함.
***
'Python 파이썬' 카테고리의 다른 글
| 파이썬 오픈 API 활용(파파고 번역) (0) | 2023.04.01 |
|---|---|
| 파이썬 이변량 분석(3) - (숫자/범주->범주형) (0) | 2023.03.15 |
| 파이썬 이변량 분석(2) - (범주형->숫자형) (0) | 2023.03.14 |
| 파이썬 이변량 분석(1) - (숫자형->숫자형) (0) | 2023.03.10 |
| 파이썬 단변량 분석(EDA) (0) | 2023.03.07 |



